Quick Understanding of Gradient Descent

You're taking a data science course or maybe have taken an interest in learning about data science on you’re own and came across gradient descent.
What is gradient descent? And why is there a picture of a dude falling from the sky onto a half pipe if this is supposed to be a data science blog? I will answer all those questions but first I want to lay out some vocabulary words that you will come across in this blog.
Linear Regression-> relationships between two continuous variables: One variable, denoted x, is regarded as the independent variable. The other variable denoted y, is the dependent variable.
Global Minimum -> is a point where the function value is smaller than all other feasible points.
Local Minimum -> is a point where the function value is smaller than nearby point but is not the global minimum of the function
Convex -> functions only having one minimum(most commonly bowl shaped)
Non-Convexed -> functions having more than one minimum(shaped like several mountain ranges and valleys)
Learning rate -> size of the steps taken to reach the minimum.
Slope -> a.k.a. gradient of a line is a number that describes both the direction and steepness of a line.
Intercept-> the point where a line meets the y axis.
Cost Function -> measures how well our prediction has done (most commonly used is the residual squared sums)
Now that we got that out the way, I’m going to answer the second question why is there a pic of a guy falling onto a half-pipe. Essentially this answers the first question. Gradient descent is used to find the values of a function’s parameters (coefficients) that minimize a cost function as far as possible. For instance if the bike lands and follows the path of the half-pipe without pedaling the bike eventually will stop at the bottom part of the half-pipe where it is completely horizontal where the height is 0 aka the minimum (warning some half-pipes may not be completely horizontal at the bottom but our’s is).
So how does it work?
We start off with our linear regression line

We then graph our slope (x) with it’s corresponding residual square sum (y)(formulas in the resource link below)

Pick a starting point on the path of the function. Where you start doesn’t really matter but most start 0.
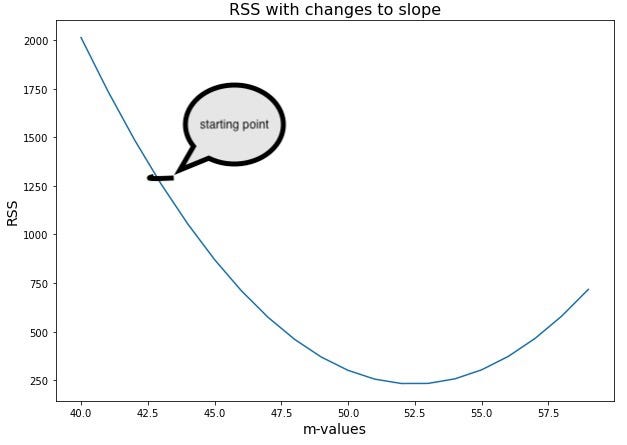
In the image above we started where the value of the weight is smaller therefore we have a negative slope. Which means we must take a step to the right to move closer to our minimum. This process is repeated till we optimize the cost function
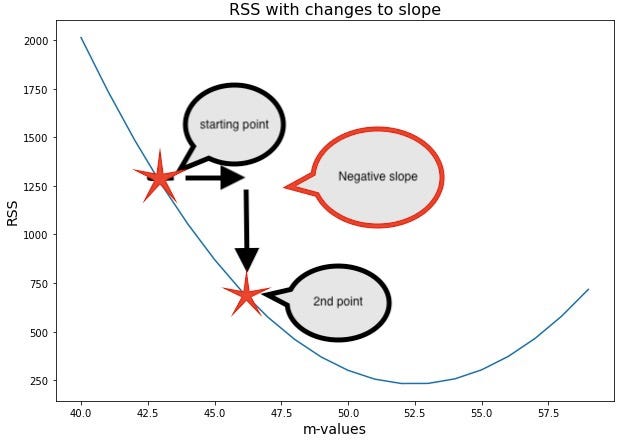
How do we know how much of a step to take or how close we are to our minimum?
The learning rate is a hyperparameter used to determine how many steps to take when descending to the minimum. The learning rate is usually a number between 0 and 1 (not always) which tells the algorithm how big of a step to take. If the learning rate is too low it might take several steps to reach the minimum. If the learning rate is too large we might take a step that surpasses our minimum and get a bigger loss than our starting point. We want to be in the godilocks zone for our learning rate where we take the least amount of steps to reach the minimum.
What are the cons of gradient descent?
Although gradient descent as a great tool to optimize your parameters for the best fit regression line it does have it’s down sides. One of it’s downsides is that if you have a very large data set it will take a while to compute the minimum therefore there are other other forms of computing gradient descent by batching. One of the forms is Stochastic Gradient Descent which uses 1 random sample at each iteration. Now how accurate might this solution be you ask? Well there is also Mini-batch stochastic gradient descent where we choose how samples we want from each iteration usually between 10 and 1000.
Hope this helps you have a better understanding of Gradient Descent. Below are some resources you can use to further your knowledge in this algorithm:
https://developers.google.com/machine-learning/crash-course/reducing-loss/gradient-descent
